
數據爬取行為的正當性邊界及合規要點
2024-03-08文/北京市集佳律師事務所 周丹丹 崔夢嘉 曹陽
隨著人工智能時代的到來,高質量訓練數據已成為大模型發展的基礎,如何合法合規獲取并構建高質量數據集成為業界越來越關注的問題。訓練數據一般來源于網絡爬取、企業直接收集、開源數據集、商業途徑購買等渠道,網絡爬取數據系其中最重要的組成部分。數據爬取行為的正當性及其邊界問題,在近年來數據作為重要生產要素的背景下,一直廣為討論。但由于目前數據保護專門立法仍在探索中,在民事法律層面,我國主要通過《反不正當競爭法》對數據爬取行為予以規制。本文將結合現有數據爬取司法案例,從數據爬取的內容、行為手段、爬取后果等角度,結合利益平衡原則,分析當前司法實務所劃定的數據爬取行為正當性邊界,梳理總結企業數據爬取行為的合規要點。
一、網絡爬蟲技術的廣泛應用
在涉數據爬取案件中,均會提到一個名詞即“爬蟲”。此“爬蟲”是一種程序腳本,是互聯網上爬取各網站、平臺數據信息內容的程序腳本的統稱,因其英文名稱“Crawler”“Spider”等而獲中文名稱“爬蟲”。
行為模式上,爬蟲按照其使用者編寫好的規則,自動為使用者爬取互聯網上的數據信息內容。它們通常使用自動化數據抓取技術來自動訪問網站,并收集、解析和存儲網站上的信息。這些信息可以是結構化或非結構化數據。在過去20多年,爬蟲技術已廣泛應用于多個領域,如搜索引擎、內容聚合、電子商務比價或市場研究、社交媒體輿情監測、競爭情報分析等等。
二、數據爬取行為的正當性邊界判斷
在涉數據爬取類不正當競爭糾紛案件中,法院通常從以下四個方面對數據爬取行為的正當性進行判斷:一是判斷數據持有者和數據獲取者之間是否具有競爭關系;二是判斷數據持有者是否享有受法律保護的競爭性數據權益;三是判斷數據獲取或使用行為是否具有不正當性;四是判斷數據獲取或使用行為是否損害經營者權益、消費者權益和市場競爭秩序。本文主要從數據獲取及使用行為的行為要件和結果要件上,總結目前司法實踐中行為正當性判斷考量因素及裁判要旨。
(一)數據爬取行為不得破壞或繞開技術措施
常見的破壞、繞開技術措施行為包括:破壞數據持有者加密系統;破壞數據持有者設置的身份認證系統、用戶登錄系統;偽裝成用戶登錄或模擬用戶行為,欺騙數據持有者的身份認證系統;破壞、繞開反爬蟲技術措施,如破壞、繞開封禁措施、IP訪問限制等。
在谷米公司訴元光公司“車來了”案【1】中,就元光公司使用爬蟲通過更換IP地址、破解加密算法等技術方式爬取谷米公司的公交實時數據,日均300萬至400萬條的行為,法院認定元光公司未經谷米公司許可,利用網絡爬蟲技術進入谷米公司服務器后臺的方式非法獲取數據的行為,具有非法占用他人無形財產權益,破壞他人市場競爭優勢,并為自己謀取競爭優勢的主觀故意,違反了誠實信用原則,擾亂了競爭秩序,構成不正當競爭。
在新浪微博訴超級星飯團案【2】中,法院認定云智聯公司抓取新浪微博非公開數據的行為涉及利用技術手段破壞或繞開微夢公司設定的訪問權限,具有不正當性。
(二)數據爬取行為應遵守Robots協議
Robots協議系通過在網站域名根目錄下以文本文檔robots.txt之形式,向爬蟲指引網站所有者對于其網站內的內容允許抑或禁止爬取的意思表示。該規范于90年代由網絡工程師們發起,迅速形成了搜索引擎領域內普遍認可、普遍遵守的技術規范。中國互聯網協會于2012年11月發布的《互聯網搜索引擎自律公約》第七條中即明確約定了“遵循國際通行的行業慣例與商業規則,遵守機器人協議(Robots協議)”,第八條規定“互聯網站所有者設置機器人協議應遵循公平、開放和促進信息自由流動的原則,限制搜索引擎抓取應有行業公認合理的正當理由,不利用機器人協議進行不正當競爭行為,積極營造鼓勵創新、公平公正的良性競爭環境。”
在我國現有的多個涉數據爬取案件中,對于爬蟲使用者違反Robots協議的行為是否構成不正當競爭,法院總體上都需要結合利益平衡原則進行綜合判斷。主要的司法觀點如下:
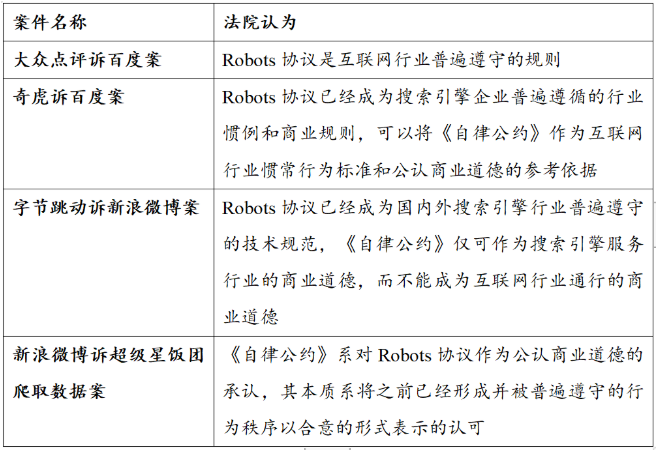
1.Robots協議是搜索引擎行業普遍遵守的技術規范,可以作為公認商業道德的參考
2.違反Robots協議的爬取行為,通常會認為具有不正當性
在百度訴奇虎“360搜索引擎”案【3】中,北京市第一中級人民法院認定360搜索引擎推出時違反Robots協議爬取百度平臺數據內容的行為構成不正當競爭。
在新浪微博訴超級星飯團案中,法院認定“根據微夢公司提交的新浪微博Robots協議,以及雙方均認可Robots協議可以約束包括網絡爬蟲在內的機器人之事實,云智聯公司在明知微夢公司限制除白名單以外的機器人抓取涉案數據的情況下仍然實施抓取涉案數據中的公開數據,顯然亦具有明顯的主觀惡意”,并結合其他因素,最終認定云智聯公司抓取新浪微博公開數據的行為具有不正當性。
3.設置Robots協議本身具有不正當性,也可能影響違反Robots協議爬取數據行為的正當性判斷
從Robots協議設置的原理而言,Robots協議設置是否具有正當、合理理由,不宜作為數據爬取者是否遵循該Robots協議的前提條件,也不應成為數據爬取者違反Robots協議爬取數據行為正當性判斷需要考量的因素。但在司法實踐中,法院通常也會對網站經營者所設置之Robots協議是否正當、合理進行判斷。
百度訴奇虎“360搜索引擎”案中,法院認為,百度在奇虎發出修改百度Robots協議的要求后應在合理期限內書面告知拒絕修改的合理理由,在百度未明確提出合理理由的情況下,奇虎在《自律公約》簽訂后實施的爬取行為不構成不正當競爭。
雖然在奇虎訴百度設置Robots協議禁止360搜索引擎爬取案【4】中,法院認為百度于《自律公約》簽訂后仍在Robots協議中專門針對360爬蟲進行限制的行為屬于歧視性措施,不具有合理、正當的理由,最終認定百度在Robots協議中針對360爬蟲進行歧視性設置的行為構成不正當競爭,但Robots協議中的針對性設置并非當然具有不正當性。在字節跳動訴新浪微博案【5】中,法院認定“Robots協議在某種意義上已經成為維系企業核心競爭力,維系市場有序競爭的一種手段。盡管Robots協議客觀上可能造成對某個或某些經營者的‘歧視’,但在不損害消費者利益、不損害公共利益、不損害競爭秩序的情況下,應當允許網站經營者通過Robots協議對其他網絡機器人的抓取進行限制,這是網站經營者經營自主權的一種體現。”
(三)從數據爬取的后果上,不得妨礙、破壞系統的正常運行,不得產生實質性替代
即使數據爬取行為不具有任何不正當性,也并不意味著數據爬取者可以對所爬取的數據任意使用。若從爬取后果的角度,存在妨礙、破壞被爬取的系統的正常運行,或后續的數據使用行為對于數據持有者的產品產生實質性替代,或損害公共利益、市場競爭秩序,也可能被法院認定為具有不正當性。
關于數據使用行為的正當性,有兩個層次:若數據來源本身不正當,則后續的數據使用行為也難謂正當;若數據來源本身不存在不正當性,也不意味著可以任意使用所爬取的數據,而仍應合理控制數據使用范圍和方式,不得對數據持有者產品產生實質性替代效果。
在大眾點評訴百度案【6】中,法院認定百度公司通過搜索技術抓取并大量全文展示來自大眾點評網的信息已經超過必要的限度,構成對大眾點評網的實質性替代,具有不正當性。
從現有司法案例可以看出,數據使用應當遵循“最少、必要”的原則,即采取對數據持有者損害最小的措施,如超出必要限度使用數據,造成對數據持有者的實質性替代,則構成不正當競爭。而在對是否超出必要限度進行考量時,可能被法院考慮的因素包括:
1.使用方式:對數據是否直接搬運使用、基本沒有創新性使用;
2.替代程度:是否導致消費者無需使用數據持有者產品,而產生了“替代”;
3.最小損害:是否存在明顯損害方式更小的數據使用方式而未采取;
4.市場效果:是否具有提升消費者福利、促進市場競爭的正向作用。
(四)利益平衡原則在行為正當性司法判斷上的運用
就數據爬取行為的規制,法院主要適用《反不正當競爭法》互聯網專條兜底條款或第二條一般性條款予以規制。而無論適用哪一條,均會涉及到利益平衡原則的運用。根據《反不正當競爭法司法解釋》第三條第二款,“人民法院應當結合案件具體情況,綜合考慮行業規則或者商業慣例、經營者的主觀狀態、交易相對人的選擇意愿、對消費者權益、市場競爭秩序、社會公共利益的影響等因素,依法判斷經營者是否違反商業道德。”
有論者提供了數據爬取中權益權衡的分析框架,【7】對于精細化衡量數據爬取各方權益具有參考作用。目前雖尚未發現法院采用如此精細量化之方式,但法院利益平衡原則一直以來都是數據爬取行為正當性評述的重點。
在筆者所代理的某搜索引擎違反Robots協議爬取數據案中,法院即綜合考慮了被訴搜索引擎違反Robots協議爬取數據作為搜索引擎服務內容予以提供,對搜索結果設置聚合產品予以主動推薦,同時考慮了被訴行為對其他經營者合法權益的損害,對消費者利益的損害,及對市場競爭秩序的影響進行判斷。
在新浪微博訴超級星飯團案中,法院認定,網絡平臺對他人抓取其公開數據應負有一定程度上的容忍義務,即對于平臺中的公開數據,基于網絡環境中數據的可集成、可交互之特點,平臺經營者應當在一定程度上容忍他人合法收集或利用其平臺中已公開的數據,否則將可能阻礙以公益研究或其他有益用途為目的的數據運用,有違互聯網互聯互通之精神。
三.企業數據爬取的合規要點
根據如上對現有司法案例的分析,本文總結提煉企業數據爬取行為的如下合規要點:
1.不可突破、繞開技術措施爬取數據,包括模擬用戶身份或行為進行系統登錄;
2.遵守Robots協議;
3.避免爬取個人信息、他人享有著作權的作品、商業秘密等;
4.避免大量、高頻地爬取數據,防止破壞網站正常經營;
5.使用數據遵循“最小必要原則”,避免產生對數據持有者的實質性替代;
6.爬取并使用開源數據集,需要遵守開源許可證。
注釋:
【1】(2017)粵03民初822號民事判決書。
【2】(2017)京0108民初24512號民事判決書。
【3】(2013)一中民初字第2668號民事判決書。
【4】(2017)京民終487號民事判決書。
【5】(2021)京民終281號民事判決書。
【6】(2016)滬73民終242號民事判決書。
【7】許可,《數據爬取的正當性及其邊界》,載《中國法學》2021年第2期。
相關關鍵詞
公司總部
機構代碼:11227
地址:北京市朝陽區建國門外大街22號賽特廣場七層
郵編:100004
總部電話:(8610)59208888
電子郵箱:mail@unitalen.com
郵件新聞接收
不要錯過我們提供的中國區知識產權保護的相關信息、服務和活動通知
提交將接受我們特別的服務優惠和知識產權保護咨詢的電子郵件




法律聲明 Unitalen Mail Box ?2016 Unitalen Attorneys at Law 版權所有 集佳知識產權代理有限公司 京ICP備11033076號 京公網安備11010502020670